Visão geral
Simplifique e operacionalize pipelines de dados com segurança em qualquer escala.
O CDP Data Engineering é o único serviço nativo da nuvem criado especificamente para equipes de engenharia de dados corporativos. Com base no Apache Spark, o Data Engineering é um conjunto de ferramentas de engenharia de dados com tudo incluído que permite a automação de orquestração com o Apache Airflow, monitoramento avançado de pipeline, solução de problemas visuais e ferramentas de gerenciamento abrangentes para agilizar os processos ETL em equipes de análise empresarial.
A engenharia de dados é totalmente integrada à Cloudera Data Platform, permitindo visibilidade e segurança de fim-a-fim com SDX, bem como integrações perfeitas com serviços CDP, como Data Warehousee Machine Learning O Data Engineering na CDP alimenta fluxos de trabalho de engenharia de dados consistentes, repetíveis e automatizados em uma plataforma de nuvem híbrida em qualquer lugar.

Casos de uso
Automatize pipelines de dados em qualquer lugar
Tenha visibilidade e controle de ETL
Mantenha a integridade dos dados
Automatize pipelines de dados em qualquer lugar
Ofereça conjuntos de dados de qualidade para CDP Data Warehouse, CDP Machine Learning ou qualquer outra ferramenta analítica.
O Data Engineering simplifica os pipelines de dados para equipes analíticas, desde o machine learning até o data warehousing e muito mais. Acelere o tempo de retorno orquestrando e automatizando pipelines para fornecer conjuntos de dados selecionados e de qualidade em qualquer lugar de forma segura e transparente.

Tenha visibilidade e controle de ETL
Gerencie de forma holística seu ciclo de vida de dados de forma transparente.
O gerenciamento do ciclo de vida dos dados e o controle de custos torna-se cada vez mais complexo ao tentar operacionalizar em escala pipelines de dados em toda a empresa.
O Data Engineering oferece um conjunto de recursos de controle operacional e visibilidade para planejamento de capacidade, automação de pipeline, captura automática de linhagem e solução de problemas em todos os casos de uso de negócios.
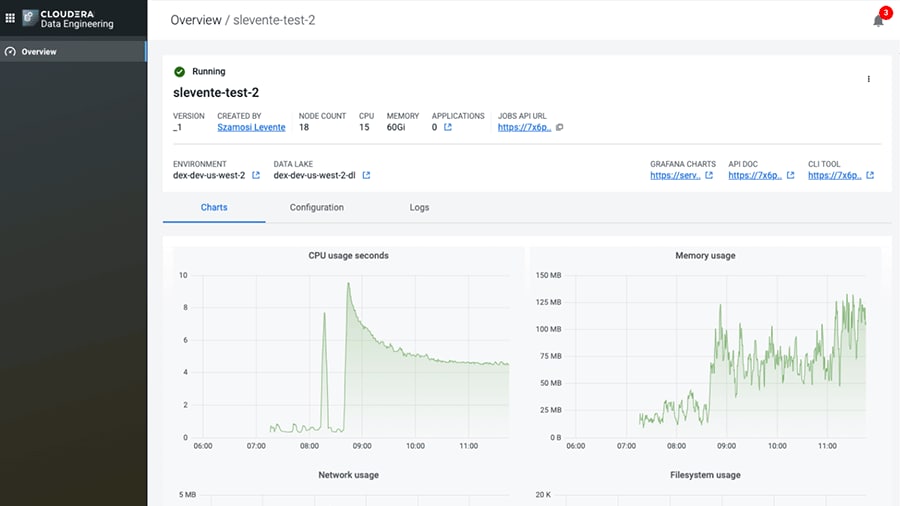
Mantenha a integridade dos dados
Visibilidade completa do pipeline de dados para proteger seus negócios.
À medida que a quantidade e a complexidade dos dados aumentam, garantir precisão e fidelidade contínuas para escalonar cargas de trabalho analíticas em toda a empresa pode ser difícil.
O Data Engineering oferece monitoramento e alertas nativos do pipeline de dados para detectar problemas com antecedência e solução de problemas visuais para resolver problemas de forma rápida antes que eles afetem seus negócios.
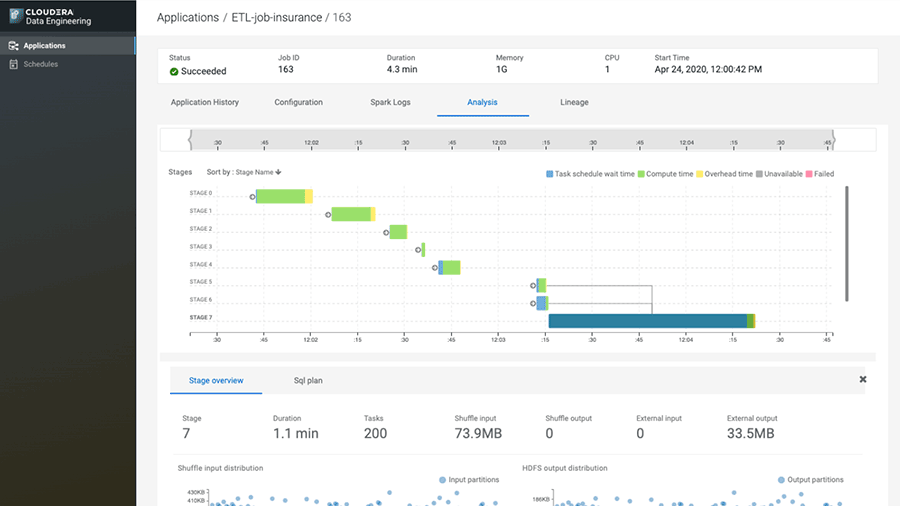
Orquestre fluxos de trabalho complexos de transformação de dados apoiados pelo Apache Airflow com centenas de operadores para atender aos requisitos analíticos de missão crítica.
O Data Engineering é conteinerizado, escalonável e portátil, com ambientes de carga de trabalho isolados e guardrails—permitindo o gerenciamento seguro de pipeline com computação elástica sob demanda para atender aos SLAs de negócios de forma econômica.
Visualize métricas de desempenho, incluindo CPU, memória e E/S em todos os estágios de seus trabalhos do Spark para identificar gargalos de desempenho e identificar a agulha no palheiro enquanto soluciona problemas.
Aproveite uma interface avançada de gerenciamento de tarefas por meio de uma CLI e APIs REST para automatizar e integrar com fluxos de trabalho existentes, como pipelines de CI/CD e ferramentas de terceiros com facilidade.
O Data Engineering oferece um serviço Spark no Kubernetes totalmente integrado que automatiza e agiliza o gerenciamento de artefatos, a segurança e o agendamento de recursos — aproveitando o Apache Yunikorn para fornecer agendamento FIFO e GANG.
A partir de uma interface centralizada, os administradores de plataforma podem gerenciar o acesso e a segurança e, em seguida, provisionar rapidamente novas cargas de trabalho e, ao mesmo tempo, monitorar facilmente a capacidade e visualizar o uso de recursos ao longo do tempo. A SDX também permite o rastreamento completo da linhagem do ciclo de vida para saber de onde os dados vieram e para onde eles estão indo.
Pronto para conhecer mais de perto?
Experimente você mesmo o Data Engineering na Cloudera Data Platform
Introdução
Demonstrações do CDP
Assista a uma demonstração on demand para saber como acelerar seus fluxos de trabalho de engenharia de dados corporativos em todos os lugares.
Conheça o tour em vídeo CDP
Veja não apenas um tour de vídeo do CDP, mas descubra também os fluxos de trabalho de engenharia de dados seguros e otimizados que podem atender melhor a sua empresa.
Recursos técnicos do CDP
Economize tempo com a centralização de informações técnicas e recursos para desenvolver suas habilidades e obter conhecimento sobre o Data Engineering da Cloudera.
Treinamento grátis
Acesse o treinamento sob demanda para se atualizar com o Data Engineering, permitindo a entrega rápida e segura de pipeline em toda a empresa.
Preços
Avalie preços, termos de faturamento, detalhes de licenciamento e taxas horárias, bem como estime custos com calculadoras úteis.
Documentação do produto
Comece com o pé direito com o planejamento de recursos, a configuração de produtos e tudo de que você precisa para as melhores práticas de engenharia de dados.