Cloudera Data Engineering
Crie, orquestre e governe pipelines de dados de nível corporativo com Apache Spark no Iceberg. Potencialize IA escalável e análises multifuncionais, da nuvem aos data centers.

VISÃO GERAL
O padrão aberto de engenharia de dados empresariais
O Data Engineering capacita as equipes empresariais a construir, automatizar e dimensionar pipelines de dados com segurança nas bases de um lakehouse aberto. Potencialize análises multifuncionais e IA para dados em qualquer lugar.
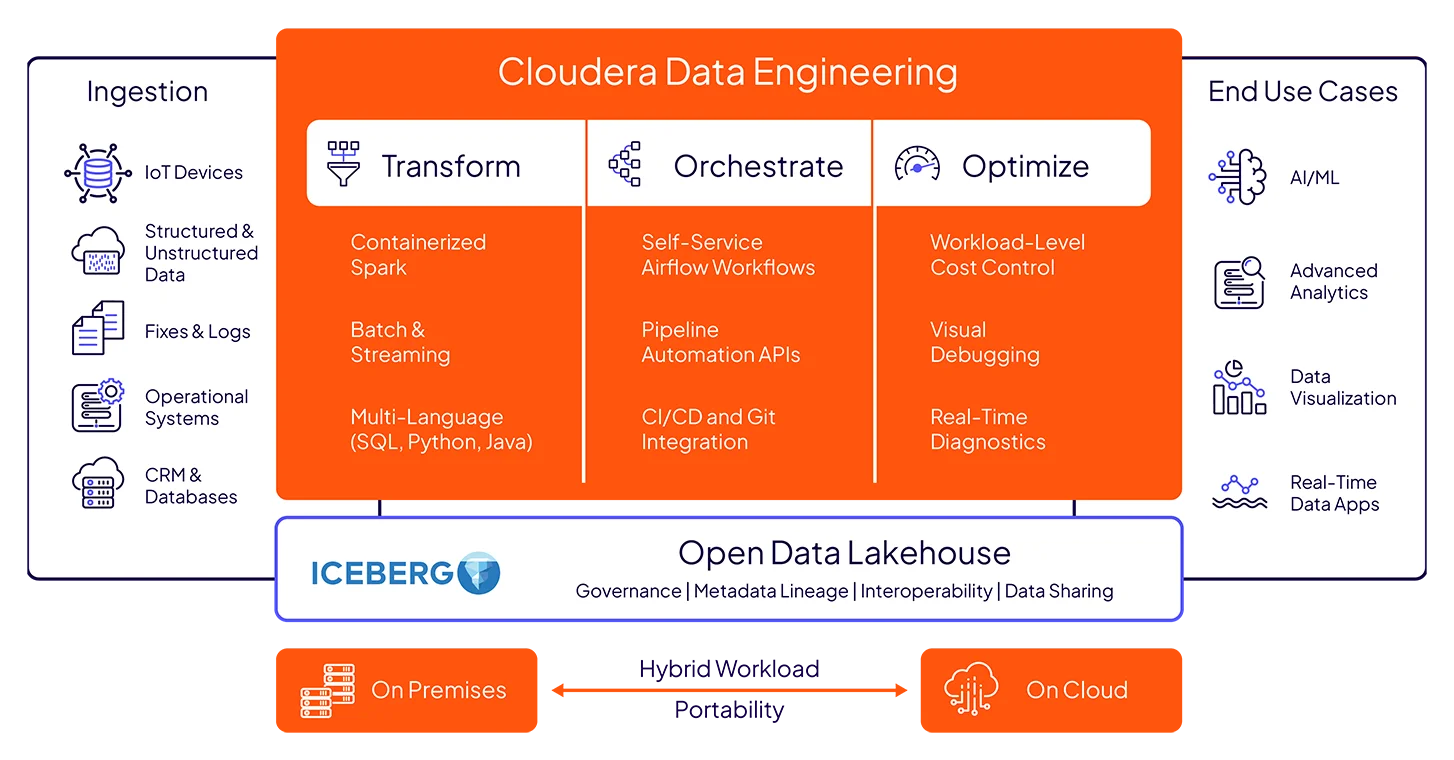
Unifique dados estruturados e dados não-estruturados com o Apache Spark no Iceberg, orquestrado pelo Airflow: totalmente aberto, sem dependência de fornecedores.
Crie, execute e gerencie pipelines de dados em qualquer lugar — nuvens, data centers ou ambientes híbridos — com flexibilidade de contêineres e governança unificada.
Tenha eficiência de custos com ferramentas de governança financeira para otimização de recursos, incluindo observabilidade em nível de carga de trabalho, escalonamento automático e compartilhamento de dados sem ETL.
CASOS DE USO
Crie pipelines de dados do inicio ao fim para acelerar a IA e a análise de dados.
-
Desenvolva pipelines escaláveis para dados em qualquer lugar
Ofereça portabilidade de cargas de trabalho, padrões abertos e escalabilidade na nuvem e em ambientes locais.
-
Acelere o DataOps com orquestração
Automatize fluxos de trabalho, itere pipelines e simplifique colaborações.
-
Compartilhamento de dados Zero-ETL
Permitir o acesso seguro e confiável aos dados, interna e externamente.
-
Monitore e otimize os custos do pipeline
Reduza o TCO com observabilidade e computação eficiente.
-
Desenvolva pipelines escaláveis para dados em qualquer lugar
Ofereça portabilidade de cargas de trabalho, padrões abertos e escalabilidade na nuvem e em ambientes locais.
-
Acelere o DataOps com orquestração
Automatize fluxos de trabalho, itere pipelines e simplifique colaborações.
-
Compartilhamento de dados Zero-ETL
Permitir o acesso seguro e confiável aos dados, interna e externamente.
-
Monitore e otimize os custos do pipeline
Reduza o TCO com observabilidade e computação eficiente.
20%
eficiência aprimorada da equipe de dados
Aumente a eficiência com portabilidade, orquestração e acesso unificado aos dados do Cloudera no local.
Execute Spark, Iceberg e Airflow de qualquer lugar, com experiência em engenharia de dados nativa da nuvem.
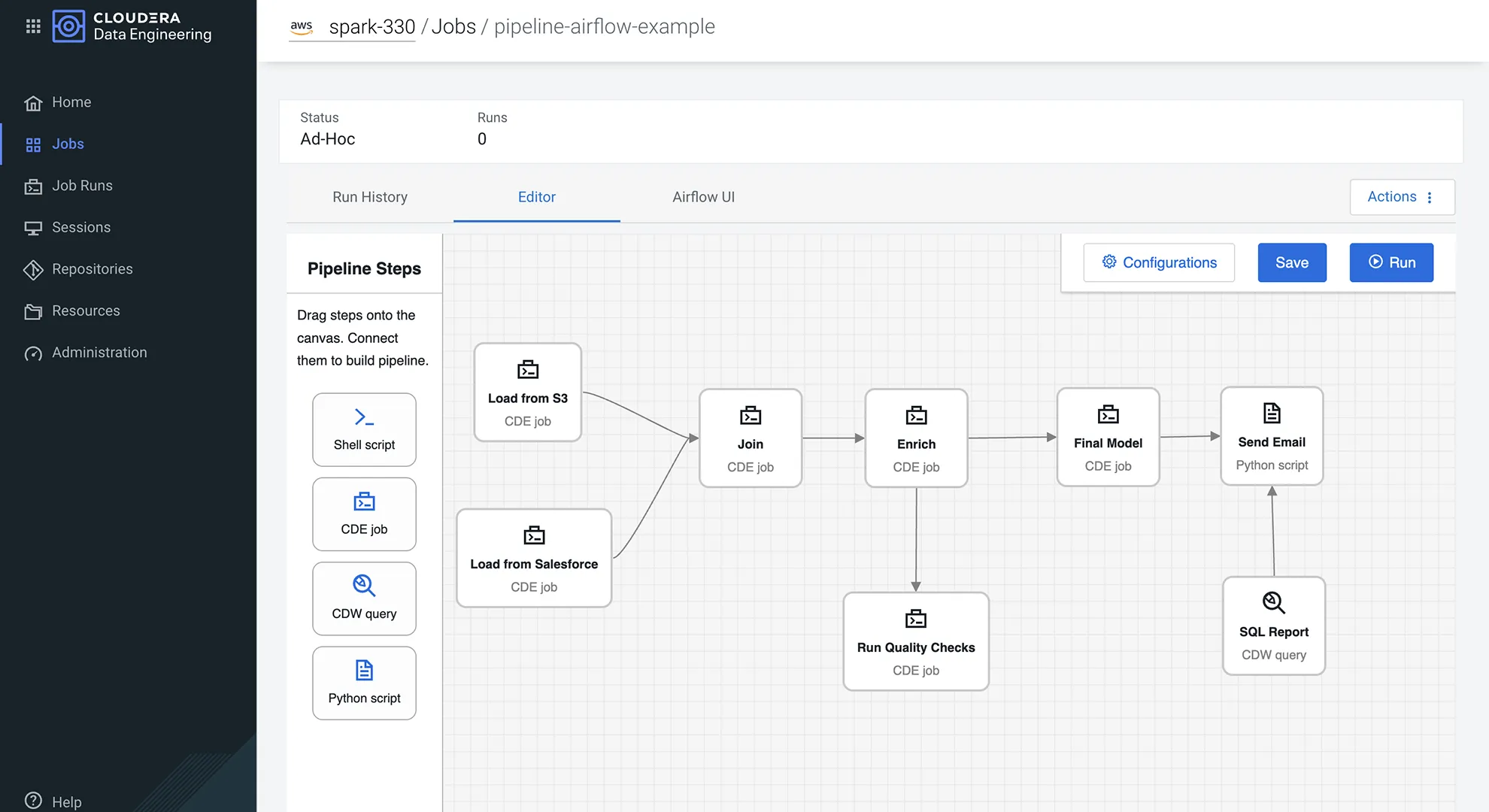
Aumente a produtividade dos profissionais com ferramentas intuitivas e segurança corporativa
Crie, teste e orquestre pipelines com Sessions e Apache Airflow.
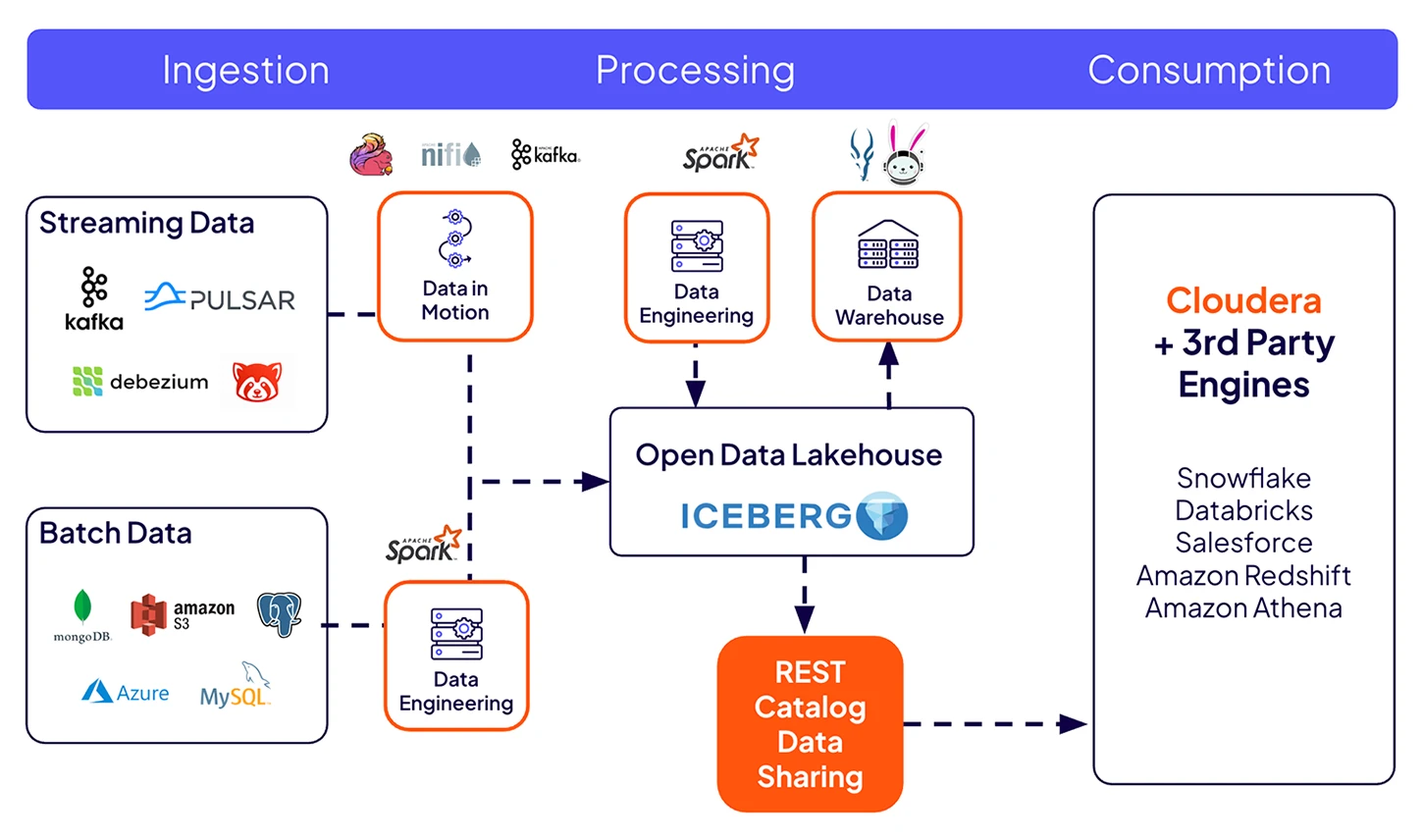
Fornecer dados atualizados para fluxos de trabalho subsequentes e plataformas externas.
Conecte-se a mecanismos externos por meio do Iceberg REST Catalog, com governança e linhagem de metadados.
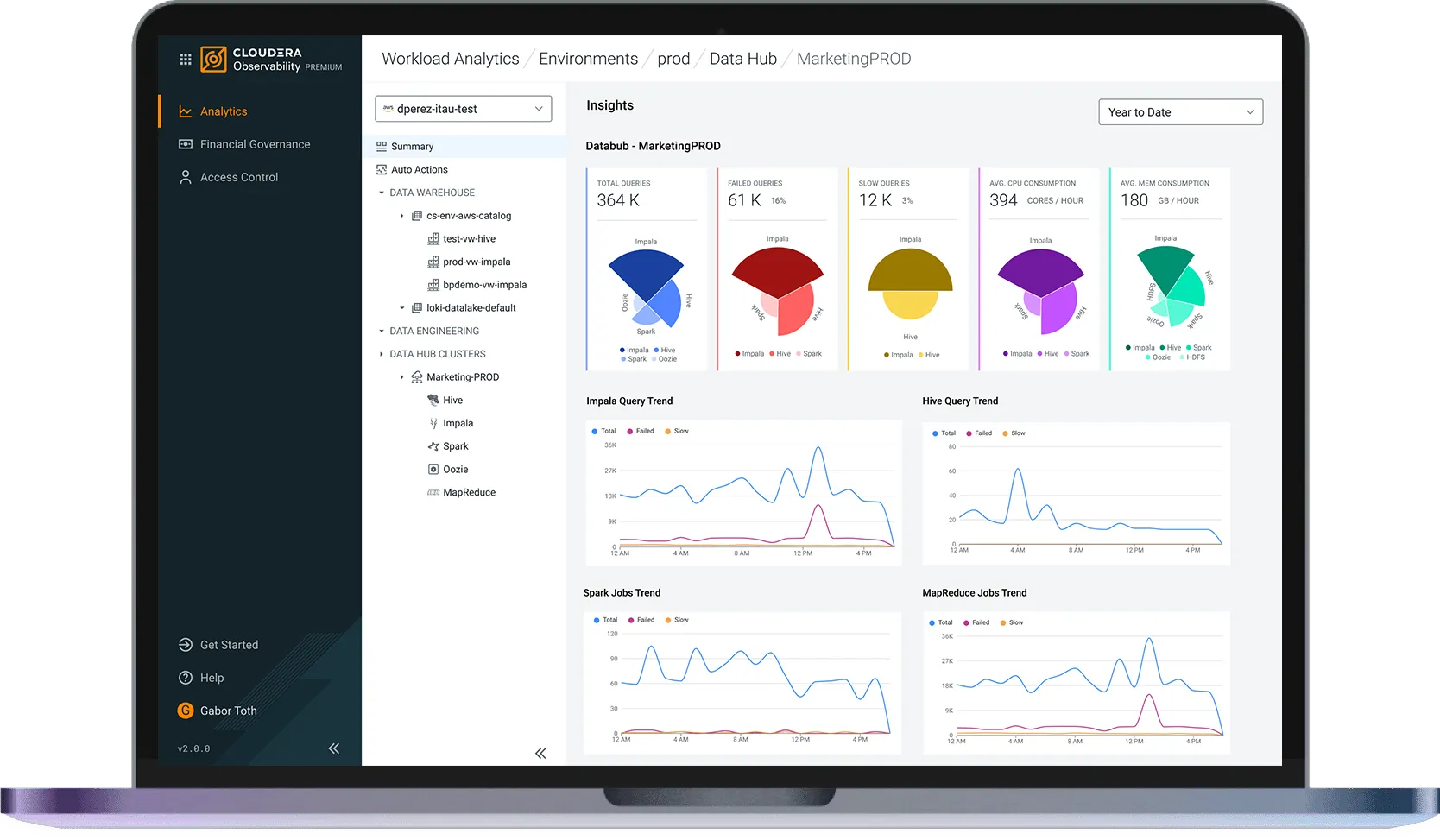
Aumente a escala de forma inteligente com governança financeira em nível de carga de trabalho
Otimize custos com insights integrados e processadores AWS Graviton energeticamente eficientes.
Migração para o Apache® Iceberg para Leigos
Leia este modelo passo a passo para migrar suas cargas de trabalho para o Apache Iceberg.

Execute pipelines escaláveis e governados com Spark on Iceberg em contêineres do data lakehouse aberto. Aproveite a revolução de esquemas, a viagem no tempo e o compartilhamento de dados externos do Iceberg em ambientes locais ou na nuvem.
Orquestração do tipo "arrastar e soltar" para fluxos de trabalho complexos, simplificando o gerenciamento de tarefas, o controle de dependências e a conectividade com ferramentas externas.
Crie sessões sob demanda para testes e iterações rápidas. Habilite o desenvolvimento remoto e seguro a partir de qualquer IDE, por exemplo, VSCode e Jupyter Notebook, com a tecnologia do Spark Connect.
Mantenha os dados atualizados capturando as alterações em nível de linha dos sistemas de origem. Automatize atualizações contínuas para construir pipelines de dados confiáveis.
Monitore os pipelines de dados fim-a-fim com linhagem integrada e gerenciamento de metadados. Impulsionado pelo Cloudera Shared Data Experience (SDX) e Cloudera Data Lineage para visibilidade automatizada, governança e insights confiáveis em ambientes híbridos.
Automatize fluxos de trabalho de pipeline em qualquer serviço com APIs robustas, esteja você trabalhando em SQL, Java, Scala ou Python. Diagnostique e resolva problemas de desempenho com perfis visuais em tempo real, completos com monitoramento e alertas integrados para cada etapa do ciclo de vida.
Recursos por tipo de cluster de Cloudera Data Engineering
| Núcleo principal | Cluster de uso geral | ||
Infraestrutura |
Cluster de dimensionamento automático | ||
| Instâncias Spot | |||
| Cloudera Shared Data Experience | |||
| Lakehouse aberto com Iceberg | |||
Spark |
Gerenciamento do ciclo de vida do trabalho | ||
| Monitoramento centralizado | |||
| Orquestração de fluxo de trabalho (Airflow) | |||
| Spark Streaming | |||
Terminais de desenvolvimento |
Sessões interativas | ||
| Conectividade IDE externa | |||
| Conector JDBC (em breve) | |||
Opções de implantação do Cloudera Data Engineering
Camada de processamento unificada em um lakehouse de dados aberto e híbrido.
Cloudera na nuvem
- Flexibilidade em várias nuvens: implante em nuvens públicas com serviços conteinerizados e com foco em APIs, sem dependência de fornecedor e totalmente interoperáveis.
- Experiência modular para desenvolvedores: utilize Apache Airflow, Spark gerenciado, APIs e IDEs — acelere o desenvolvimento com colaborações iterativas.
- Escalabilidade elástica: as cargas de trabalho do Spark são dimensionadas automaticamente de forma dinâmica, otimizando os custos com base no uso.
Cloudera on premises
- Controle sua implementação: implante em nuvens públicas com serviços conteinerizados e com foco em APIs, sem dependência de fornecedor e totalmente interoperáveis.
- Experiência pronta para a nuvem: tenha os mesmos serviços modulares e conteinerizados da nuvem, desenvolvidos para portabilidade e escalabilidade híbridas.
- Desenvolvido para empresas: aproveite a integração rápida, o acesso a IDEs externos e controles de acesso refinados por padrão.
CLIENTES
Confiança para as equipes transformarem dados híbridos em impacto nos negócios.
 Transporte
GEODIS
Transporte
GEODIS
 Serviços financeiros
Nord/LB
Serviços financeiros
Nord/LB
 Manufatura e automotivo
International
Manufatura e automotivo
International
Conectores, integrações e parceiros.
Construa pipelines em um ecossistema de dados aberto e interoperável. Integre-se com os principais mecanismos, provedores de nuvem e ferramentas em toda a sua infraestrutura de dados moderna.
Processamento de dados
Data lakes e warehouses
Orquestração de dados
Ingestão de streaming
Mecanismo NoSQL
Data lakes e warehouses
Provedor de serviços de nuvem
Provedor de serviços de nuvem
Provedor de serviços de nuvem
Provedor de serviços de nuvem
Orquestração de contêineres
Data warehouse
Dê o próximo passo
Aprofunde-se nos detalhes e explore os poderosos recursos do Cloudera Data Engineering.
Conheça o produto Data Engineering
Conheça os bastidores da Cloudera Engineering fazendo um tour pelo produto.
Documentação de engenharia de dados
Aprofunde-se nos detalhes de como iniciar com o Cloudera Data Engineering.
Explore mais produtos
Analise grandes quantidades de dados para milhares de usuários simultâneos sem comprometer a velocidade, o custo ou a segurança.
Tome decisões inteligentes com uma plataforma flexível que processa quaisquer dados, em qualquer lugar, para análises acionáveis e IA confiável.
Acelere a tomada de decisão orientada por dados, da pesquisa à produção, com uma plataforma segura, escalonável e aberta para IA empresarial.
Colete e transfira seus dados de qualquer fonte para qualquer destino de maneira simples, segura, escalonável e com um excelente custo-benefício.