Produtos Cloudera
A única plataforma de dados e IA capaz de levar a nuvem para qualquer lugar, fornecendo serviços de dados conteinerizados de fim-a-fim em uma única plataforma.

Capacitamos empresas com uma plataforma de dados e IA que transforma 100% dos dados em qualquer lugar em insights confiáveis e valiosos para gerar impacto crucial nos negócios em todos os lugares.
Nuvem em qualquer lugar
Controle cargas de trabalho e dados em diversas infraestruturas com uma experiência de nuvem totalmente interoperável e consistente, sem a necessidade de refatoração de cargas de trabalho ou reescrita de aplicativos. Mantenha a flexibilidade de forma integrada, reduzindo o TCO e os custos de migração.
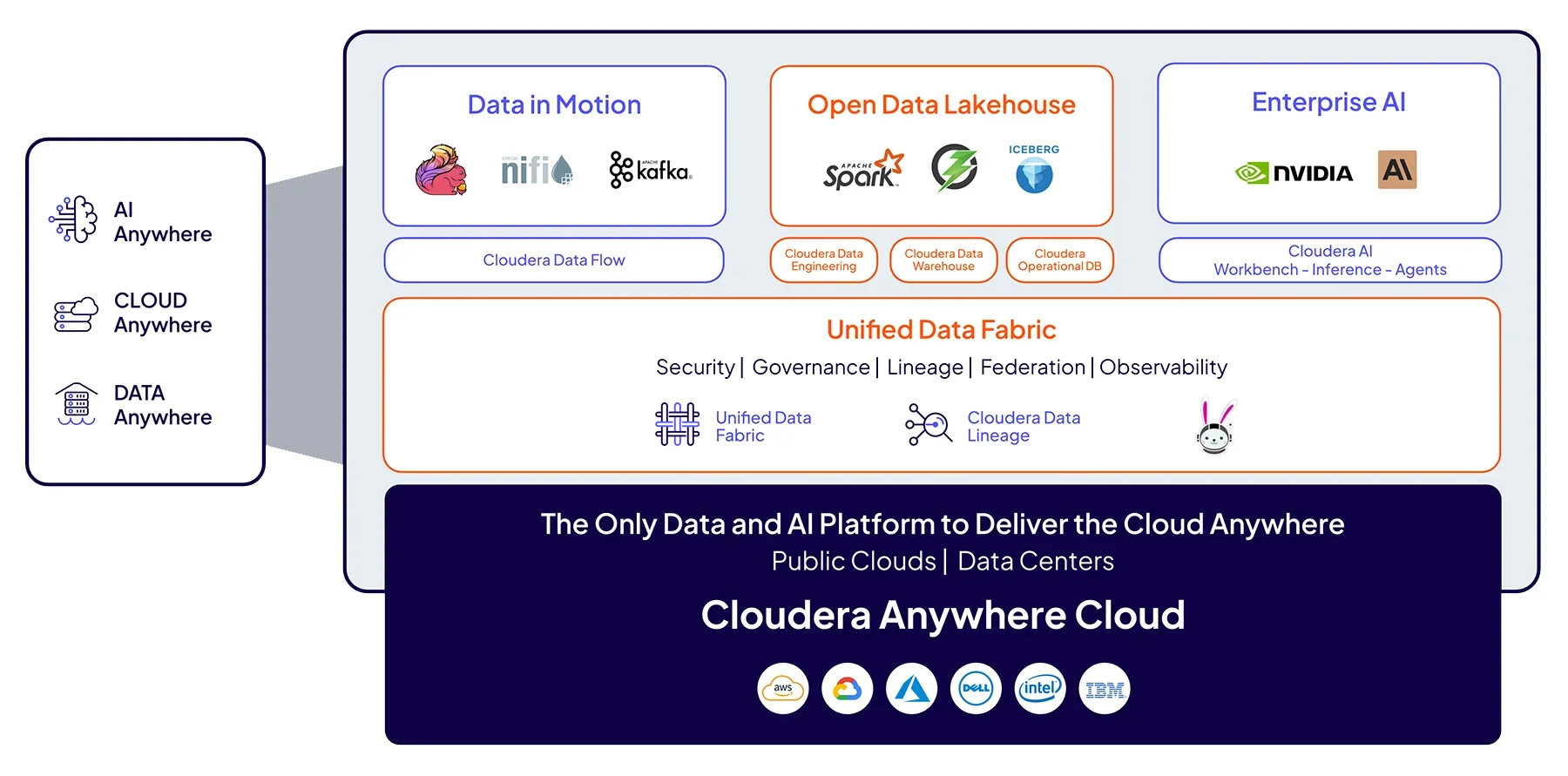
Cloudera Platform
A única plataforma de dados e IA do setor em que grandes organizações confiam para levar a IA aos dados onde quer que eles estejam.
Armazenamento de Objetos Cloudera
Aumente a escalabilidade para bilhões de objetos com total compatibilidade com o S3 e um custo total de propriedade (TCO) menor, graças ao armazenamento de objetos baseado no Apache Ozone.
Cloudera Data Services
Tenha a agilidade da nuvem para dados e aplicativos de IA, em qualquer lugar, com serviços poderosos para acelerar a inovação.
IA empresarial
Inicie, acelere e capitalize as oportunidades da IA com controle total, segurança e governança completas. Crie e execute IA privada para aplicações e agentes de nível empresarial, em grande escala, reduzindo custos sem comprometer a conformidade. Saiba mais
Acelere a tomada de decisão orientada por dados, da pesquisa à produção, com uma plataforma segura, escalonável e aberta para IA empresarial.
Serviço de inferência de IA da Cloudera
Implante e escale aplicativos, agentes e assistentes de IA privados com velocidade, segurança e eficiência incomparáveis.
Descubra fluxos de trabalho privados de IA generativa e IA agêntica para todos os níveis de habilidade, com agilidade low-code e controle total do código.
Leve o poder da IA para o seu negócio de forma segura e em grande escala, garantindo que cada informação seja rastreável, explicável e confiável.
Crie, treine e implemente IA privada com segurança, utilizando desenvolvimento colaborativo unificado de IA em dados governados, em qualquer lugar.
Aceleradores para projetos de ML (AMPs)
Explore a estrutura fim-a-fim para desenvolver, implementar e monitorar instantaneamente aplicativos de machine learning prontos para empresas.
Data lakehouse aberto
Forneça dados unificados, seguros e confiáveis em todo o ciclo de vida dos dados, integrando-se aos sistemas corporativos existentes, graças ao formato de tabela aberta do Apache Iceberg para grandes conjuntos de dados. Saiba mais
Crie, orquestre e governe com segurança pipelines de dados de nível corporativo com Apache Spark no Iceberg.
Banco de Dados Operacional Cloudera
Potencialize aplicativos críticos em tempo real com uma solução NoSQL de alto desempenho desenvolvida para as demandas de ambientes híbridos.
Analise grandes quantidades de dados para milhares de usuários simultâneos sem comprometer a velocidade, o custo ou a segurança.
Gerencie com confiança seus maiores desafios de dados com o único open data lakehouse do setor para dados e IA incorporada no Apache Iceberg.
Conecte fontes de dados em plataformas, nuvens e data centers, fornecendo dados prontos para IA que sejam rápidos, seguros e otimizados.
Data fabric unificada
Reduza os riscos e garanta a conformidade, democratizando o acesso autônomo a dados confiáveis com gerenciamento centralizado de linhagem de dados e metadados em toda a empresa, controles de acesso e governança. Saiba mais

Cloudera Shared Data Experience
Unificando segurança e governança com formatos de armazenamento abertos nativos em nuvem, o SDX reduz custos, aumenta a agilidade e os insights do negócio, e permite que você permaneça em conformidade ao gerenciar centralizadamente todos os seus dados.
Gerencie e compreenda a linhagem de dados e os metadados para ter visibilidade completa em ambientes híbridos complexos.
Descubra, classifique e crie perfis de todos os seus dados, garantindo a conformidade com os controles baseados em políticas para informações sensíveis ou regulamentadas.
Monitore e otimize as implantações da Cloudera em qualquer lugar que estejam para melhorar a utilização de recursos e a governança financeira.
Visualização de dados Cloudera
Permita que os usuários de negócios explorem dados gerenciados, colaborem e tenham insights de forma rápida e fácil com painéis de controle baseados em IA.
Data in Motion
Forneça insights verdadeiros, em tempo real e baseados em dados sobre qualquer infraestrutura, permitindo decisões mais rápidas, aumentando a eficiência operacional, melhorando a satisfação do cliente e acelerando o crescimento da receita. Saiba mais
Colete e transfira seus dados de qualquer fonte para qualquer destino de maneira simples, segura, escalonável e com um excelente custo-benefício.
Utilize o Kafka e o Flink para criar serviços e aplicativos de alto desempenho e em tempo real para impulsionar seus negócios.
Tenha controle dos seus dados de dispositivos edge com coleta e gestão de dados edge em tempo real.
Opções de implantação da Cloudera
Implante a Cloudera em qualquer lugar com uma experiência nativa, portátil e consistente.
Cloudera na nuvem
Os serviços de dados Cloudera na nuvem são gerenciados pela Cloudera, mas diferentemente de outros serviços em nuvem pública, os seus dados permanecerão sempre sob seu controle em seu VPC. A Cloudera é executada no AWS, no Azure e no Google Cloud.
- Controle os custos da nuvem acelerando automaticamente as workloads quando necessário e suspendendo a operação quando concluída
- Gerenciar workloads: Isole e controle workloads com base no tipo de usuário, tipo de workload e prioridade de workload.
- Quebre silos: Controle centralizado dos dados de clientes e operacionais em ambientes híbridos e multinuvem.
Cloudera no local
O Cloudera on-premises moderniza as implementações tradicionais de clusters monolíticos; fornece cargas de trabalho analíticas, transacionais e de machine learning poderosas; e oferece suporte a análises tradicionais e elásticas, além de armazenamento de objetos escalável em uma plataforma de dados híbrida.
- Rápido time-to-value por meio do provisionamento simples e por autoatendimento de análises fáceis de usar, prontas em questão de minutos.
- Maior economia com utilização otimizada de recursos e dissociação de computação e armazenamento
- Desempenho previsível isolamento da carga de trabalho e multi-tenancy gerenciada
Nossos clientes
 Serviços financeiros
United Overseas Bank
Serviços financeiros
United Overseas Bank
 Telecomunicações
Amdocs
Telecomunicações
Amdocs
 Transporte
Halifax International Airport Authority
Transporte
Halifax International Airport Authority