Democratizar dados para IA utilizando interoperabilidade entre mecanismos e colaboração de dados sem cópia.




Como o Catálogo REST do Cloudera Iceberg possibilita organizações abertas e preparadas para IA
Há muito tempo interoperabilidade é uma palavra da moda, não uma capacidade com a qual as empresas possam contar na prática. Em vez disso, arquitetos de dados frequentemente ficam costurando sistemas fragmentados, diretores de dados enfrentam riscos enormes e bloqueios de fornecedores devido à governança isolada, e líderes de plataforma são impedidos de apresentar uma visão uniforme de dados a suas equipes. Seja por meio de fusões, estratégias multinuvem ou parcerias externas, o padrão se repete: custos crescentes, inovação mais lenta e capacidade limitada de ampliar IA com segurança.
Na Cloudera, ajudamos nossos clientes a enfrentar esses desafios, como camadas de metadados desconectadas, pipelines de dados duplicados e modelos de governança que não se estendem entre ferramentas, sempre buscando possibilitar empresas abertas, prontas para IA, que liberam a interoperabilidade em larga escala.
Por que clareza é importante para a IA empresarial
Para dimensionar as cargas de trabalho de IA, as organizações precisam de visibilidade e controle sobre os dados que as alimentam. A inteligência de metadados desempenha um papel fundamental nessa equação, possibilitando que as organizações entendam onde os dados residem, como estão estruturados e como são utilizados em diferentes equipes e ferramentas.
Com padrões abertos como o Apache Iceberg e o Iceberg REST Catalog, as empresas contam com uma camada unificada de metadados que oferece suporte ao compartilhamento de dados sem ETL, impõe governança e possibilita a interoperabilidade segura entre mecanismos de análise e IA. Essa base transforma a infraestrutura fragmentada em uma arquitetura de dados conectada e pronta para IA, na qual os metadados tornam-se a chave para acelerar o acesso a insights enquanto mantêm a confiança.
Aberto, seguro e simples: o catálogo REST do Cloudera Iceberg.
O Catálogo REST do Cloudera Iceberg alimenta nosso data lakehouse aberto e ajuda as organizações a simplificar a arquitetura, reduzir a duplicação e estender o acesso seguro aos dados onde for necessário.
Ele atua como uma camada de metadados universal e interoperável e disponibiliza o acesso de cópia zero às tabelas do Iceberg entre ferramentas, nuvens e equipes, possibilitando que ferramentas de código aberto e de terceiros acessem os mesmos dados. Recursos e benefícios:
- Aberto e independente de mecanismo: disponibiliza APIs baseadas em padrões que suportam ferramentas como Athena, Databricks, Redshift e Snowflake, possibilitando interoperabilidade sem dependência de fornecedor.
- Desacoplado por design: abstrai os mecanismos de consulta dos metastores de backend, reduzindo a complexidade e aumentando a portabilidade entre ambientes.
- Acesso a metadados em tempo real: suporta consultas rápidas e atualizadas de metadados em metastores compatíveis com o Iceberg, melhorando a visibilidade dos dados entre as equipes.
- Governado e seguro: Estende os controles de acesso refinados, as permissões em nível de linha e a integração do gerenciamento de acesso à identidade corporativa (IAM) (como LDAP e OAuth2) a todos os sistemas conectados, garantindo a aplicação consistente de políticas em escala.
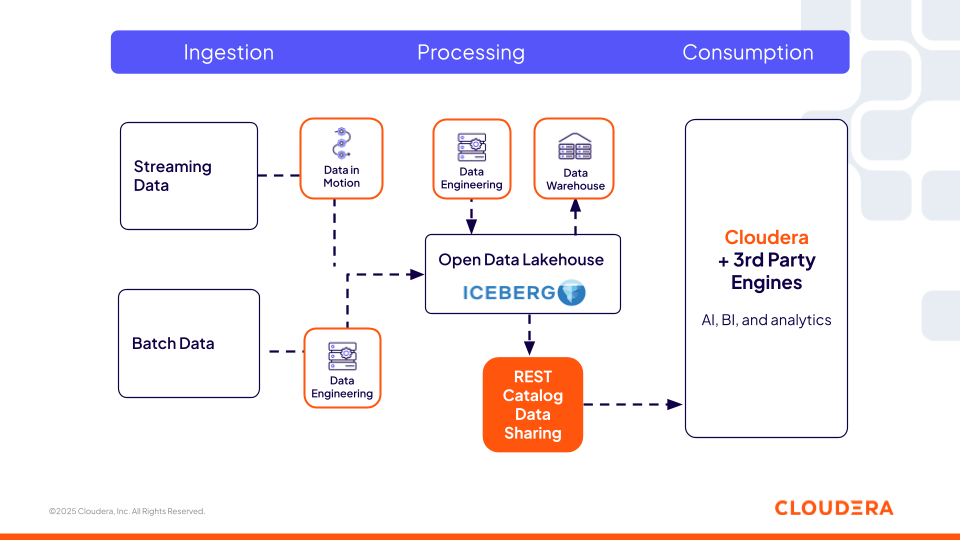
Figura 1. O Iceberg REST Catalog da Cloudera oferece uma camada de metadados universal e interoperável, possibilitando que ferramentas de código aberto e de terceiros acessem os mesmos dados.
Casos de uso do mundo real e impacto do Catálogo REST do Iceberg
Os exemplos reais a seguir ilustram como as organizações estão usando o Catálogo Iceberg REST para simplificar sua pilha de dados, reduzir o custo total de propriedade (TCO) e acelerar o tempo de retorno ao valor – tudo isso enquanto mantêm os dados onde eles pertencem.
Juntos, esses exemplos demonstram como a abordagem aberta e interoperável da Cloudera acelera os resultados da IA, impulsiona a eficiência operacional em escala empresarial e possibilita segurança e conformidade.
Compartilhamento de dados: Expanda as aplicações de IA para mais de 3 mil usuários multiplataforma.
Uma fabricante de automóveis de luxo enfrentou desafios crescentes para compartilhar dados com segurança com um parceiro externo utilizando o Databricks. Os métodos tradicionais dependiam da duplicação de dados, o que acarretava custos, complexidade e inflexibilidade arquitetônica.
Ao adotar o Iceberg REST Catalog, o cliente estabeleceu um compartilhamento de dados seguro e sem ETL entre sistemas internos e plataformas externas. Essa abordagem aberta e baseada em padrões permitiu que escolhessem as melhores ferramentas para o trabalho utilizando o Spark para pipelines de dados complexos e o Impala para análises SQL rápidas. Com essa base a empresa expandiu as aplicações de IA para mais de 3 mil usuários, mantendo total governança e controle sobre o acesso aos dados.
Otimização do Data Warehouse: reduza os custos de movimentação de dados em 74%.
Após uma fusão, uma empresa global de satélites encontrou obstáculos consideráveis na unificação de dados fragmentados e armazenados em sistemas proprietários. Sem uma camada de dados uniforme e interoperável, suas iniciativas de IA e análise de dados tiveram uma expansão lenta e foram difíceis de gerenciar.
A arquitetura de data lakehouse aberta da Cloudera, alimentada pelo Iceberg REST Catalog, ajudou o cliente a consolidar esses silos e estabelecer uma base única confiável de dados para todas as suas cargas de trabalho de IA e análise. Na consulta direta das tabelas do Iceberg gerenciadas no S3, eles eliminaram a necessidade de pipelines de dados redundantes e esforços de replatforming, resultando em uma redução de 74% nos custos de movimentação de dados.
Demonstração: uma análise mais detalhada do compartilhamento de dados por meio do catálogo REST Iceberg da Cloudera
Esta demonstração interativa dá vida ao Catálogo REST Iceberg por meio de um cenário de serviços financeiros. No fictício Parent Bank, diversas equipes usam suas ferramentas preferidas, como Snowflake e AWS Athena, para acessar com segurança uma única fonte de dados governada, tudo isso sem ETL complexo nem movimentação custosa de dados.
Para uma análise mais aprofundada desta oferta e de como ela pode beneficiar a sua organização, explore estes recursos:
- Acesse nossa página de produtos para saber mais sobre o open data lakehouse da Cloudera.
- Leia o comunicado de imprensa para ver o anúncio completo sobre a visão da Cloudera para o compartilhamento aberto de dados.