Desbloqueando o potencial da IA corporativa: destilação de conhecimento para análise de suporte ao cliente





Hoje, as empresas enfrentam um grande desafio: desejam aproveitar modelos avançados de IA para se manter competitivas, mas precisam equilibrar os altos custos dos modelos de linguagem de larga escala (LLMs) baseados em nuvem com as exigências de conformidade em privacidade de dados.
Como, então, explorar IA de ponta sem extrapolar orçamentos ou expor informações confidenciais? Na Cloudera, desenvolvemos uma solução que transforma esse desafio em oportunidade — usando dados sintéticos gerados a partir de dados privados e destilação de conhecimento para criar sistemas de IA precisos, econômicos e em conformidade com regulamentações.
Neste artigo, discutimos como o Cloudera Synthetic Data Generation Studio — parte do Cloudera AI Studios— permite que as organizações aproveitem a inovação em IA mesmo quando os dados reais são escassos ou sensíveis.
Caso de Uso e Principais Conclusões
Caso de uso: com base em um caso interno, mostramos como melhoramos significativamente a performance e a vazão do pipeline de tíquetes de suporte da Cloudera, utilizando destilação de conhecimento com dados sintéticos gerados a partir de dados privados, tudo isso mantendo a privacidade e a conformidade regulatória.
Principais aprendizados:
Privacidade de dados como vantagem competitiva: dados sintéticos permitem inovação sem riscos regulatórios.
Desempenho econômico: modelos menores e ajustados superam alternativas maiores e mais pesadas em recursos.
Aplicabilidade ampla: a mesma abordagem pode atender a casos que vão de detecção de fraudes até atendimento ao cliente personalizado.
Desafio Empresarial: Equilibrar a Velocidade e a Precisão do Modelo de IA Sem Comprometer a Privacidade dos Dados
A equipe de suporte da Cloudera utiliza modelos de IA para analisar e resumir tíquetes de suporte em tempo real. O sistema recebe como entrada comentários de clientes ou de agentes de suporte da Cloudera. Em seguida, analisa cada comentário e extrai análises como sentimento e resumo. Essas análises são cruciais para aprimorar a experiência dos clientes da Cloudera.
Devido à natureza sensível dos dados de clientes processados nesse pipeline, apenas modelos que rodam em ambientes locais podem ser utilizados, e nenhum dado de cliente pode ser compartilhado com fontes externas.
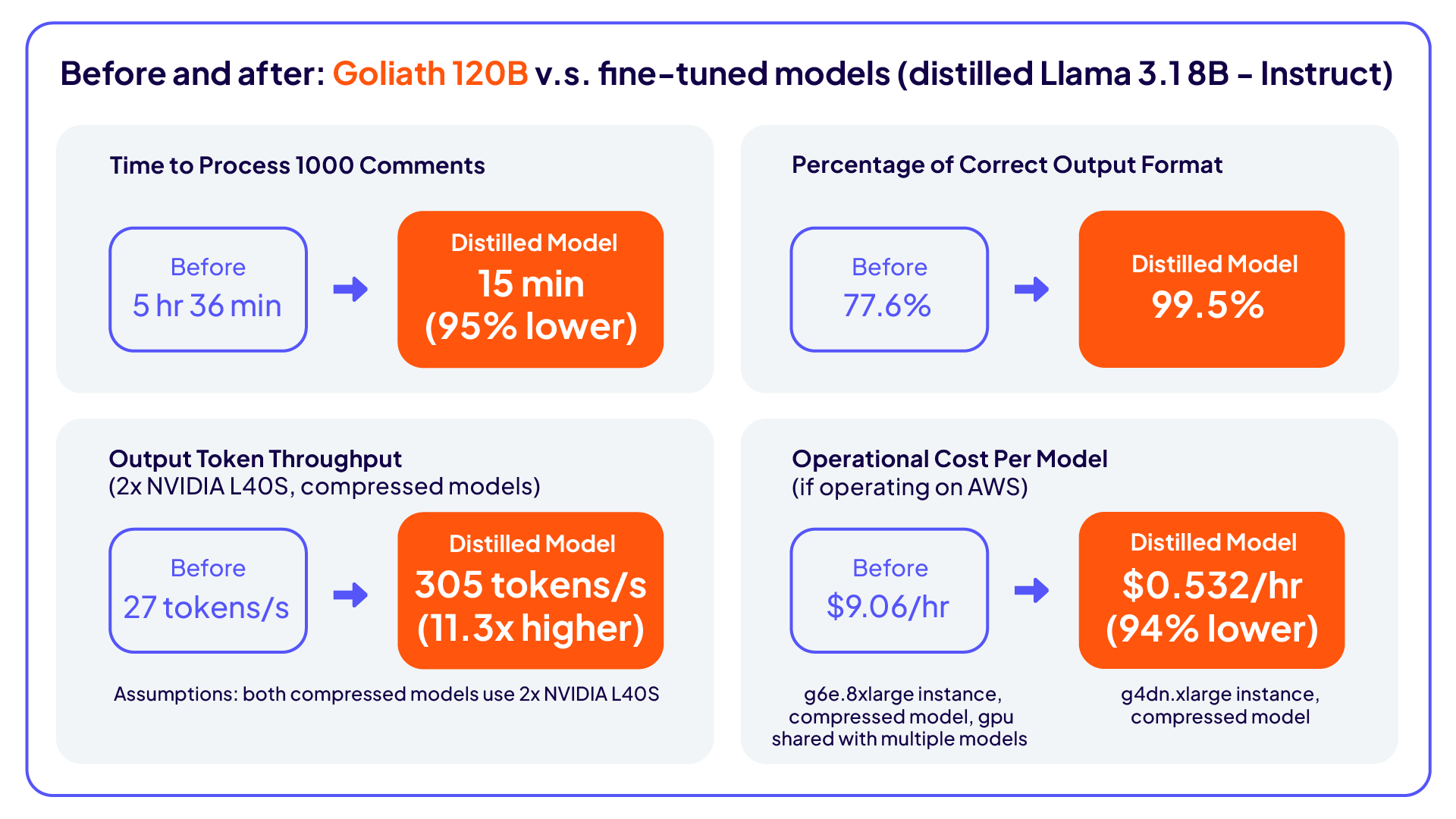
Inicialmente, para analisar os comentários, a equipe utilizava LLMs locais (Goliath 120B), que atendiam aos requisitos básicos de desempenho, mas apresentavam lentidão na velocidade e no desempenho de geração: em média, cada solicitação levava de 12 a 15 segundos para ser processada, enquanto as requisições chegavam a cada 30 segundos. A aderência ao resultado esperado era de 77,5%, e a precisão de geração era inferior à dos modelos proprietários — um gargalo para a escalabilidade e para o desempenho dos LLMs.
Os desafios de usar grandes LLMs locais (Goliath-120B) ficaram claros: tempos de resposta mais lentos, custos mais altos, menor precisão de geração em comparação com modelos de última geração baseados em nuvem e riscos de conformidade.
Grandes organizações enfrentam trade-offs semelhantes — equilibrar a precisão e a velocidade da IA com os riscos de exposição de dados.
Solução da Cloudera: Destilação de Conhecimento com Dados Privados
A inovação da Cloudera está em uma abordagem com privacidade em primeiro lugar para a destilação de conhecimento.
Em vez de treinar modelos com dados brutos de clientes, que envolvem riscos regulatórios e de exposição, geramos conjuntos de dados sintéticos usando o Cloudera Synthetic Data Studio. Essa nova ferramenta low-code, parte do Cloudera AI, simulou interações do mundo real — perguntas técnicas, cenários de troubleshooting e muito mais — sem nunca expor informações privadas.
Gerar interações sintéticas de suporte ao cliente trouxe benefícios regulatórios e de segurança, além de permitir que a equipe enviasse os dados sintéticos para LLMs de última geração baseados em nuvem, a fim de extrair insights, como sentimento de clientes, a partir dos LLMs de melhor desempenho. Esses LLMs em nuvem forneceram extração de informações muito mais precisa do que grandes LLMs locais, tornando-se uma fonte ideal para destilar insights de alta qualidade.
A solução de dados sintéticos da Cloudera eliminou riscos de conformidade e privacidade e produziu os dados sintéticos de maior qualidade, até melhores do que os gerados por LLMs locais de grande porte. Essa abordagem abriu caminho para destilar conhecimento de modelos de ponta em LLMs menores, resolvendo o mesmo problema do Goliath-120B, mas com menor custo e maior precisão.
Nosso Processo
Geração de dados: usando o fluxo de trabalho do Synthetic Data Studio, a equipe elaborou um prompt instruindo o modelo Claude Sonnet a gerar perguntas e respostas de clientes. O prompt orientava o LLM a criar tickets de suporte, impor o tom e detalhar a estrutura. Além disso, fornecemos uma lista de tópicos presentes em dados reais (como suporte ao cliente para Cloudera AI ou Cloudera Data Warehouse) e usamos tópicos iniciais para garantir diversidade e representatividade nos tickets gerados.
Ajuste fino: com apenas os dados filtrados, a equipe dividiu o conjunto em treino e desenvolvimento, e destilou conhecimento do modelo Claude Sonnet para um Meta Llama3.1-8B-instruct. A equipe executou múltiplos experimentos, selecionando os parâmetros de ajuste fino que maximizassem o desempenho do LLM destilado.
Avaliação: usando o fluxo de avaliação do Synthetic Data Studio, a equipe elaborou um prompt para instruir um LLM-as-a-judge sobre como verificar a qualidade dos dados gerados e filtrar amostras de baixa qualidade.
Combinando avaliações humanas e automatizadas (LLM-as-a-judge), a equipe pontuou perguntas e respostas de tíquetes de suporte de clientes reais. O time da Cloudera concentrou-se nas respostas em que os LLMs implantados e destilados divergiam e reportou a taxa de vitórias de cada LLM. Além disso, mediram melhorias em termos de tempo médio de execução, aderência ao resultado esperado e custo de implantação do modelo.
Os Resultados
Velocidade aprimorada: o tempo de processamento caiu 95%.
Melhor estrutura de saída: a aderência ao resultado esperado subiu de 77,5% para 99,5%.
Maior precisão de LLMs: ao comparar o LLM destilado menor (Llama 3.1 8B) com o LLM implantado (Goliath 120B), a taxa de vitórias foi de 70% vs. 30% usando o Phi-4 como avaliador e de 63% vs. 37% em avaliações humanas.
Redução de custos e ganhos de eficiência: o LLM destilado menor reduziu a necessidade de computação e memória, aumentou a escalabilidade em tempo real, manteve a privacidade dos dados e melhorou o rendimento em 11x.
Os resultados são claros: as empresas podem alcançar excelência em IA sem comprometer a privacidade dos dados. Ao sintetizar dados de treinamento e aplicar destilação de conhecimento, os negócios evitam os trade-offs entre inovação e conformidade.
Dados Sintéticos Permitem Inovação Sem Risco Regulatório
Ao desenvolver uma abordagem de destilação de conhecimento, a Cloudera alcançou uma redução de 95% no tempo de processamento, aumentou a aderência da estrutura de saída para 99,5% e implantou um modelo Llama 3.1 8B destilado, que superou o anterior Goliath 120B em precisão, com 70% de vantagem segundo o avaliador Phi-4 e 63% em avaliações humanas.
Esse método eliminou os riscos de conformidade ao evitar o uso direto de dados sensíveis e também proporcionou um aumento de 11 vezes no rendimento, demonstrando que modelos menores e ajustados podem superar alternativas maiores e com alto consumo de recursos tanto em velocidade quanto em precisão.
Experimente nosso AMP para explorar como usar dados sintéticos privados a fim de destilar conhecimento de um modelo grande para um modelo menor em um caso de suporte ao cliente.