
Construindo Aplicações RAG - Os detalhes fazem a diferença
A criação de aplicativos de geração aumentada por recuperação (RAG) pode se tornar complexa rapidamente, exigindo cuidado com a ingestão, processamento e recuperação de dados. Tradicionalmente, os desenvolvedores têm navegado pelas etapas de fragmentação de dados, inserção de embeddings e integração de bancos de dados vetoriais.
No entanto, uma das armadilhas mais comuns ao implementar uma solução RAG é não compreender como esses componentes são interdependentes. Os desenvolvedores devem questionar: "Nossos dados podem ser fragmentados como estão ou devemos refiná-los antes?".
O Cloudera Data Flow e os processadores exclusivos RAG Pipeline da Cloudera simplificam o processo complexo de refinar dados não estruturados por meio de particionamento, permitindo uma fragmentação mais eficaz e uma incorporação de vetores de maior qualidade. Embora um particionamento ou fragmentação mal projetados possa prejudicar o desempenho e a qualidade dos embedding, as ferramentas da Cloudera eliminam grande parte dessa complexidade, otimizando o desenvolvimento de soluções RAG eficientes e confiáveis.
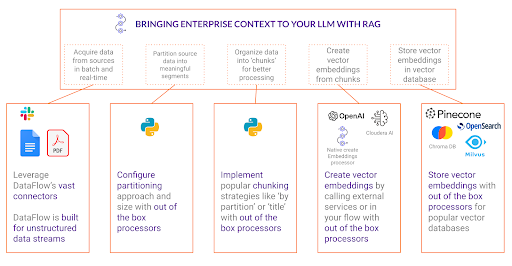
Vamos explorar os estágios críticos de um fluxo de trabalho de RAG — particionamento, fragmentação, incorporação e inserção — e demonstrar como a tecnologia da Cloudera simplifica cada etapa.
Particionamento de dados: O fundamento do RAG
A primeira etapa essencial de um fluxo de trabalho de RAG é o particionamento. Esse processo envolve a decomposição de grandes fontes de dados, às vezes não estruturados, em segmentos significativos, permitindo a iteração programática sobre dados não estruturados. É claro que o processo de recuperação ainda é possível sem o particionamento, mas quanto mais controle granular houver sobre o processamento, maior será a flexibilidade para criar fluxos para diferentes fontes de dados. O particionamento garante que os dados sejam estruturados em partes gerenciáveis que se alinhem à forma como os usuários consultam as informações.
As estratégias de particionamento variam de acordo com a natureza dos dados. Por exemplo, particionar por cabeçalhos de seção permite uma recuperação mais organizada ao processar documentos longos, como manuais de usuário. Em contrapartida, o particionamento pode envolver a divisão do conteúdo por carimbos de data e hora para preservar o fluxo de conversação em dados como logs de bate-papo. Outra consideração importante são os limites de token. Como a maioria dos modelos de embedding tem um tamanho de token predefinido que pode ser processado de uma só vez, o particionamento deve estar alinhado a essas restrições para garantir o desempenho ideal.
Uma abordagem de particionamento bem definida ajuda a manter a precisão, a eficiência e a usabilidade dos aplicativos de RAG. Os desenvolvedores podem otimizar a qualidade da resposta garantindo que apenas os dados mais relevantes sejam recuperados e passados para o LLM, minimizando a sobrecarga computacional desnecessária.
Chunking: Garantindo a preservação do contexto
Após a conclusão do particionamento, a etapa seguinte é a fragmentação. Ela consiste em agrupar partições relacionadas para manter um contexto significativo. Enquanto o particionamento divide o conteúdo em componentes fundamentais, a fragmentação garante que esses componentes mantenham seus relacionamentos, evitando a perda de contexto.
Por exemplo, uma cláusula ou regulamento pode abranger vários parágrafos em documentos jurídicos. Se forem particionados de forma muito restrita, o significado pode ser perdido ao recuperar o conteúdo com base na consulta de um usuário. A fragmentação ajuda a reunir segmentos de texto relacionados em uma unidade logicamente completa. Isso garante que, quando o usuário faz uma consulta, o modelo recebe informações contextuais suficientes para gerar uma resposta precisa e relevante.
As estratégias de fragmentação variam de acordo com a natureza do conjunto de dados. Algumas abordagens fazem a fragmentação simples de comprimento fixo, em que os segmentos são agrupados com base em um número predefinido de tokens. Estratégias mais avançadas podem envolver a fragmentação do título de um documento com o texto relacionado.
A fragmentação eficaz melhora a precisão da pesquisa, otimiza a latência de recuperação e garante que as respostas geradas pelo LLM sejam contextualmente adequadas e precisas. Além disso, ao determinar uma estratégia de fragmentação que maximiza a preservação do contexto, você pode orientar a decisão do seu modelo de embedding com o conhecimento predefinido dos tamanhos dos fragmentos.
Embedding: Transformando Texto em Vetores Pesquisáveis
Com fragmentos bem estruturados, o próximo passo no fluxo de trabalho de RAG é a incorporação, ou embedding. Embeddings são representações numéricas de texto que permitem que as máquinas compreendam e comparem o significado semântico de diferentes segmentos de texto. Sem a incorporação, os aplicativos de RAG se limitariam a simples pesquisas por palavras-chave, que não contam com a compreensão contextual da verdadeira recuperação semântica.
A incorporação é um processo de várias etapas que consiste em tokenização, transformação vetorial e armazenamento. Quando um fragmento de texto passa por um modelo de embedding, primeiro ele é dividido em tokens. Esses tokens são então convertidos em um vetor de alta dimensão que captura a essência do texto em um formato adequado para buscas de similaridade matemática, como a distância euclidiana (L2) e a similaridade de cosseno.
Escolher o modelo certo de embedding é fundamental. Alguns modelos são otimizados para recuperação de uso geral, enquanto outros são ajustados para aplicações específicas do domínio, como documentos jurídicos, médicos ou técnicos. Outra consideração importante é a dimensionalidade dos vetores, que deve estar alinhada com o esquema do banco de dados vetorial. Uma incompatibilidade no tamanho do vetor pode resultar em pesquisas ineficientes ou problemas de compatibilidade.
Uma vez que os fragmentos de texto são incorporados em representações vetoriais, eles se tornam pesquisáveis usando métricas de similaridade. Isso possibilita a recuperação altamente eficiente do conteúdo mais relevante com base nas consultas dos usuários, melhorando muito a precisão e a capacidade de resposta dos aplicativos impulsionados por RAG.
O Cloudera Data Flow oferece um processador de embedding incrivelmente poderoso e fácil de usar que aprimora as funcionalidades dos seus fluxos de dados, permitindo que você use um modelo dentro do contexto do processador. Não há necessidade de chamar uma API (não é necessária uma GPU). O processador tem três propriedades simples:
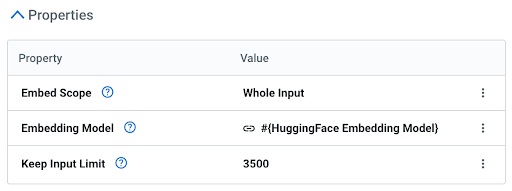
Isso dá a você controle granular para escolher o melhor modelo de embedding para cada fluxo de dados.
Inserção dos fragmentos incorporados em um banco de dados vetorial: possibilitando uma recuperação eficiente
A etapa final do fluxo de trabalho de RAG é inserir os fragmentos incorporados em um banco de dados vetorial. Os bancos de dados vetoriais são projetados para realizar buscas por similaridade em alta velocidade, permitindo a recuperação eficiente de conteúdo relevante quando um usuário faz uma consulta.
Diferente dos bancos de dados tradicionais, que dependem da indexação estruturada para correspondências exatas, os bancos de dados vetoriais usam pesquisas de similaridade e algoritmos como ANN e KNN para encontrar embeddings que correspondam de forma próxima à consulta do usuário. É isso que permite que os aplicativos de RAG recuperem conteúdo semanticamente relevante, mesmo que as palavras da consulta sejam diferentes do texto armazenado.
Depois que os dados incorporados são inseridos no banco de dados vetorial, o sistema está pronto para consultas em tempo real. Quando um usuário envia uma solicitação, a consulta é transformada em um embedding, comparada com os vetores armazenados, e os resultados mais relevantes são recuperados, formando a base da resposta do LLM.
O Cloudera Data Flow oferece muitos processadores de conexão VectorDB, como Milvus, Pinecone e Chroma, com mais a caminho.
Simplifique o desenvolvimento do seu aplicativo RAG hoje mesmo
Com o Cloudera Data Flow e seus processadores especializados de RAG Pipeline, as organizações agora podem criar, implantar e otimizar aplicativos de RAG com uma facilidade sem precedentes. Ao eliminar grande parte da complexidade técnica, as soluções da Cloudera permitem que os desenvolvedores se concentrem em aprimorar a precisão da recuperação, otimizar a geração de respostas e melhorar a experiência geral do usuário.
As empresas podem implementar rapidamente soluções RAG que escalam de maneira eficiente e fornecem respostas precisas e sensíveis ao contexto, aproveitando os processadores exclusivos de particionamento, fragmentação, embedding e integração VectorDB da Cloudera.
Se quiser explorar como a Cloudera pode ajudar a simplificar o desenvolvimento de aplicativos de RAG, entre em contato com nossa equipe para solicitar uma demonstração ou consulte a documentação técnica para obter mais informações.
Fique atento para um próximo mergulho profundo nas técnicas avançadas de otimização do RAG!
Saiba mais:
Para explorar os novos recursos do Cloudera Data Flow 2.9 e descobrir como ele pode transformar seus pipelines de dados, assista a este vídeo.
