
As bases abertas da Cloudera possibilitam que as organizações acessem 100% de seus dados, onde quer que estejam armazenados.
Em diversos setores, as equipes de dados estão repensando como construir e executar sistemas que façam mais do que armazenar informações: elas buscam transformar dados em inteligência. Igualmente importante, eles precisam que esses sistemas interoperem. Os modelos de IA, os fluxos de recursos, os relatórios de Business Intelligence (BI) e os trabalhos em lote geralmente abrangem várias equipes e mecanismos. Compartilhar dados além dessas fronteiras sem copiar ou refatorar é agora um requisito fundamental.
Tradicionalmente, as organizações têm se baseado em uma arquitetura de duas camadas: Data Warehouse otimizados para BI e geração de relatórios, e data lakes projetados para IA e aprendizado de máquina (ML) em larga escala. Essa separação teve um custo: movimentação complexa de dados, engenharia especializada e armazenamento duplicado em sistemas que raramente permaneciam sincronizados.
A arquitetura open lakehouse da Cloudera enfrenta esse desafio, reunindo cargas de trabalho analíticas (BI, consultas ad hoc) e IA (IA preditiva e generativa, ou GenAI) em uma única base de dados governada. Com formatos de tabela aberta como o Apache Iceberg, essa arquitetura unificada de dados permite que as organizações tragam computação para os dados (e não o contrário) e apresenta a base para rodar cargas de trabalho de IA mais próximas dos dados. As cargas de trabalho de IA no lakehouse podem operar diretamente em dados governados, versionados e de alta qualidade.
A Cloudera é a única empresa de plataforma de dados e IA que leva a IA aos dados em qualquer lugar. Aproveitando nossa comprovada base de código aberto, oferecemos uma experiência de nuvem consistente que integra nuvens públicas, data centers e edge.
A importância de bases abertas para a execução de cargas de trabalho de IA
Na última década, as empresas aprenderam que desempenho e escalabilidade, por si só, não são suficientes e que flexibilidade e interoperabilidade determinam o sucesso a longo prazo. As cargas de trabalho de IA, em particular, dependem da capacidade de usar fontes de dados, estruturas e ferramentas distintas sem serem limitadas por formatos ou sistemas proprietários.
É aí que formatos de tabela abertos como o Apache Iceberg remodelaram a arquitetura das plataformas de dados. O Iceberg separa a definição lógica de uma tabela de seu layout físico de armazenamento, possibilitando que múltiplos motores e frameworks leiam e escrevam os mesmos dados com garantias transacionais completas. Essa abertura possibilita a evolução da infraestrutura e a adoção de novos mecanismos de computação sem a necessidade de reescrever os pipelines.
A execução de pipelines de nível de produção exige uma plataforma unificada que possa conectar dados, modelos e governança em todos os estágios do ciclo de vida da IA. No centro, há pipelines de engenharia de dados e recursos que transformam constantemente dados brutos estruturados, semiestruturados e dados não-estruturados em recursos prontos para IA, mantendo a linhagem e a reprodutibilidade para treinamento e avaliação de modelos.
Além do aprendizado de máquina tradicional, a GenAI introduz novos requisitos operacionais. As equipes precisam de infraestrutura e acesso a dados para geração aumentada por recuperação (RAG), ajuste fino de grandes modelos de linguagem (LLMs) em dados privados e construção de fluxos de trabalho agentes que combinam modelos, prompts e protocolos de contexto de modelo (MCPs) (APIs) para resolver tarefas específicas do domínio. Essas cargas de trabalho dependem de dados tabulares e dados não-estruturados (texto, documentos, imagens e embeddings), todos gerenciados por um único plano de dados e metadados. Além disso, uma camada de inferência escalável é essencial para implantar e disponibilizar esses modelos de forma segura e eficiente.
À medida que as cargas de trabalho de IA ficam cada vez mais multimodais e autônomas, o acesso a catálogos e metadados torna-se igualmente crítico. Os fluxos de trabalho de IA, os sistemas de recuperação de dados e os agentes autônomos dependem de metadados para descobrir conjuntos de dados, reproduzir estados de treinamento e manter linhagens. Um catálogo aberto oferece uma maneira universal para esses sistemas consultarem, registrarem e rastrearem conjuntos de dados, independentemente de onde ou como eles são processados.
A plataforma aberta da Cloudera permite que as organizações ofereçam suporte a todo o espectro de cargas de trabalho analíticas, preventivas e de IA generativa (GenAI).
Plataforma Unificada de Dados e IA da Cloudera
O data lakehouse aberto da Cloudera unifica engenharia de dados, análise e IA na mesma arquitetura governada, com base em fundamentos abertos como o Apache Iceberg e o catálogo REST. A plataforma foi projetada com base no princípio de que as cargas de trabalho (sejam analíticas ou de IA) devem operar onde os dados já residem. Eliminando o atrito de mover ou duplicar dados, as equipes podem construir pipelines contínuos que abrangem ingestão, transformação, análise e operações de modelos, com total linhagem e governança.
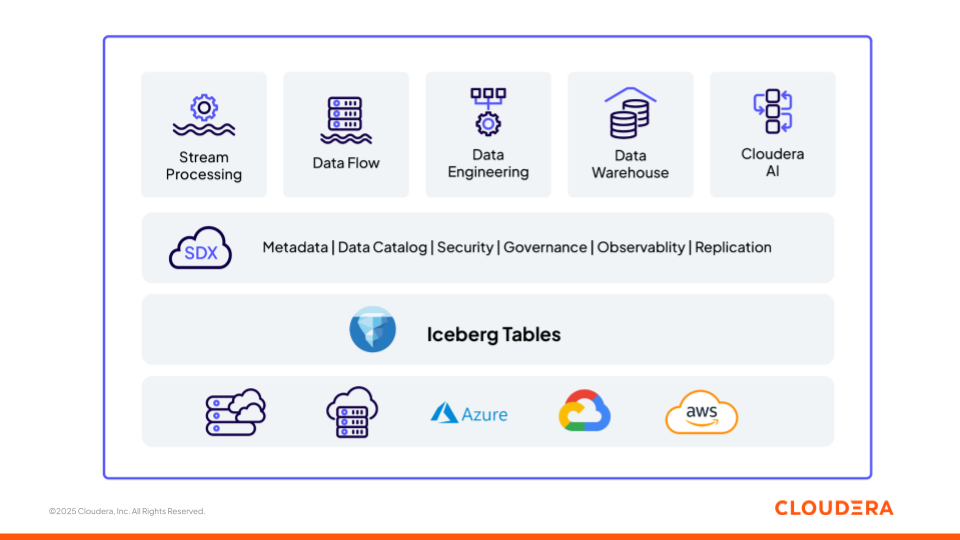
Figura 1: Plataforma de dados e IA da Cloudera construída sobre bases abertas (Apache Iceberg)
Agora vamos analisar como os diferentes componentes da plataforma Cloudera (Figura 1) auxiliam as equipes na criação de pipelines de ML e aplicações GenAI, bem como nas diferentes etapas do ciclo de vida de dados e IA, da ingestão à inferência, operando como uma plataforma interoperável. Cada componente é construído com base em padrões abertos, garantindo flexibilidade e interoperabilidade entre ambientes.
Armazenamento: Apache Iceberg
O Apache Iceberg é o formato de tabela aberto, versionado e transacional que sustenta a arquitetura lakehouse da Cloudera. O Iceberg permite a evolução do esquema, a viagem no tempo e as operações atômicas, possibilitando que cargas de trabalho analíticas e de IA operem de forma consistente nos mesmos dados governados. A Cloudera oferece uma base governada e versionada que garante que cada tarefa de modelo, solicitação ou recuperação seja baseada em uma visão consistente e rastreável dos dados.
Os recursos nativos do Iceberg, como a evolução do esquema, também se alinham estreitamente com a evolução dos conjuntos de dados de IA. Armazenamentos de recursos, conjuntos de dados de treinamento e corpora de recuperação podem compartilhar as mesmas tabelas Iceberg no lago da Cloudera, usando instantâneos para congelar visualizações consistentes para treinamento, enquanto novos dados continuam fluindo para inferência. Isso elimina a divisão entre tabelas analíticas e armazenamento específico de IA.
Ingestão: Cloudera Data in Motion
O Cloudera DataFlow, construído sobre o Apache NiFi, forma a base do movimento contínuo de dados para dentro do lakehouse. Permite a ingestão de baixa latência de diversas fontes empresariais, ou bancos de dados, APIs, dispositivos IoT e registros de eventos, para suportar cargas de trabalho em lote e de streaming. Inovações recentes na integração nativa do NiFi com o Apache Iceberg agora permitem que os dados sejam escritos diretamente open lakehouse, sem staging intermediário. Essa forte integração entre o NiFi e o Iceberg reduz a complexidade do pipeline e aproxima a ingestão do próprio formato de tabela aberta.
Em casos de uso em tempo real, NiFi, Apache Kafka e Apache Flink formam um tecido de ingestão baseado em eventos: NiFi orquestra e roteia dados, Kafka entrega streaming duradouro e Flink possibilita o enriquecimento em tempo real antes de persistir dados no Iceberg. Este design garante que os dados permaneçam atualizados e controlados em todos os consumidores subsequentes. Esse fluxo contínuo de dados multimodais é também o que alimenta as cargas de trabalho de IA no lakehouse. Ao disponibilizar dados em tempo real continuamente em tabelas Iceberg sob governança consistente, as empresas podem fornecer aos sistemas GenAI informações específicas e oportunas para domínio, tornando os pipelines RAG e fluxos de trabalho agentes mais precisos, fundamentados e confiáveis.
Catálogo: Cloudera Iceberg REST Catalog
O Cloudera Iceberg REST Catalog (baseado na especificação REST aberta) oferece um serviço de metadados centralizado e interoperável que permite que qualquer mecanismo de terceiros (como Snowflake, Redshift e Databricks) que suporte a especificação aberta tenha acesso sem cópia às tabelas do Iceberg. Esse é um aspecto fundamental para as organizações, pois elas não estão restritas a apenas um mecanismo de computação oferecido por uma plataforma e, portanto, têm a flexibilidade de escolher a melhor computação para a tarefa. Os usuários podem usar suas ferramentas preferidas enquanto as mesmas políticas de segurança e governança oferecidas pela Cloudera seguem os dados em todos os lugares, garantindo consistência em todos os ambientes.
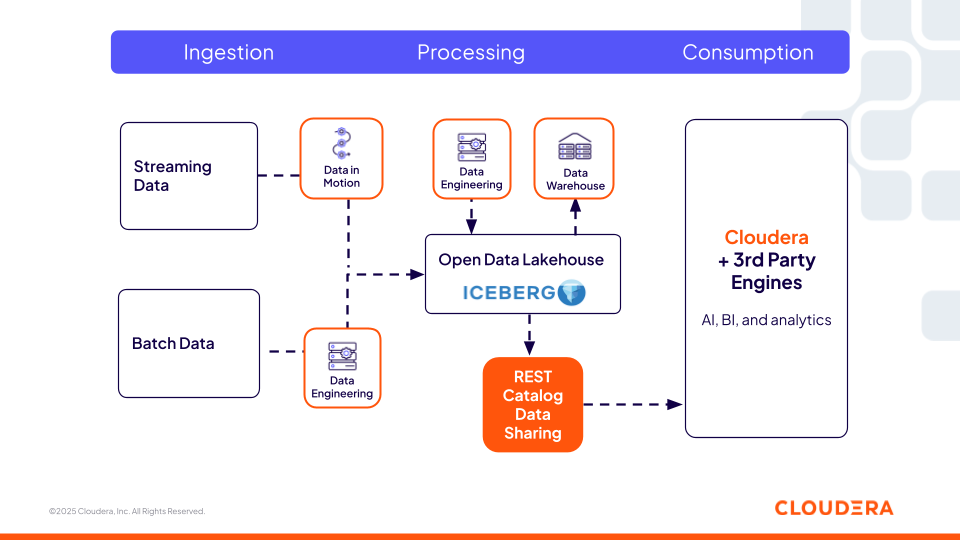
Figura 2: O catálogo REST Iceberg da Cloudera possibilita a interoperabilidade com mecanismos de terceiros.
Essa camada de catálogo é fundamental para pipelines de engenharia de recursos, fluxos de trabalho com agentes e sistemas de recuperação, possibilitando localizar e acessar conjuntos de dados governados de forma dinâmica. Os agentes de IA podem consultar as tabelas do Iceberg usando o Catálogo REST, assim como um grafo de conhecimento de dados empresariais. Eles podem descobrir tabelas disponíveis, interpretar seus esquemas e analisar metadados das tabelas, como particionamento, snapshots e linhagem, para determinar quais conjuntos de dados utilizar.
Segurança e governança: Cloudera SDX
O Cloudera Shared Data Experience (SDX) é o framework unificado de segurança e governança que abrange todos os serviços, desde a ingestão até a inferência. O SDX proporciona uma camada única e consistente para linhagem de dados, auditoria, controle de acesso e aplicação de políticas, garantindo que toda carga de trabalho herde o mesmo modelo de segurança, independentemente de onde rode. Ele se integra a sistemas de identidade corporativos (LDAP, SSO, OAuth) e oferece suporte a controles de acesso refinados, baseados em funções e atributos, em dados estruturados e dados não-estruturados.
Ao acoplar SDX com a fundação open lakehouse, a Cloudera garante que dados, modelos e agentes de IA operem dentro do mesmo limite governado, entregando transparência, reprodutibilidade e confiança tanto para cargas analíticas quanto para cargas de trabalho GenAI.
Cloudera Serviços de Dados e IA
A camada de serviços unificados reúne todas as capacidades funcionais que as equipes precisam para transformar, analisar e operacionalizar a IA, tudo isso trabalhando com os mesmos dados governados.
Data Engineering
A Cloudera Data Engineering, construída sobre o Apache Spark e o Apache Airflow de código aberto, oferece um serviço serverless para construir, orquestrar e escalar pipelines de dados diretamente em tabelas Iceberg, possibilitando pipelines ETL e funcionalidades confiáveis e reproduzíveis para cargas de trabalho de analytics e IA em ambientes híbridos.
Serviços de IA
A camada de serviços de IA da Cloudera operacionaliza todo o ciclo de vida da IA, começando pelo treinamento e ajuste fino do modelo até a implantação segura, tudo rodando nativamente sobre a mesma base de dados governada com o Iceberg. Ela unifica o desenvolvimento de modelos, o registro e a inferência em um único fluxo de trabalho que conecta a engenharia de dados e as operações de IA.
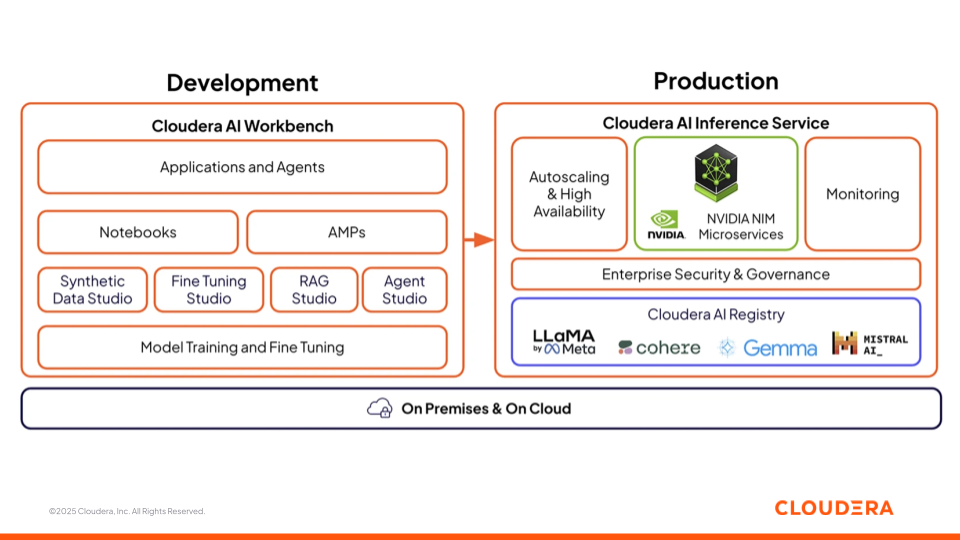
Figura 3: Oferta da Cloudera AI com AI Workbench e Serviço de Inferência
Cloudera AI Workbench
Cloudera AI Workbench é o ambiente colaborativo onde cientistas de dados, analistas e engenheiros desenvolvem, ajustam e testam modelos. Reúne notebooks, construtores de aplicações low-code (AMPs) e estúdios especializados para cada etapa do desenvolvimento de IA. Para acelerar o desenvolvimento e a implementação de IA, o Cloudera AI Workbench oferece suporte a quatro estúdios de IA que preenchem a lacuna entre as equipes de negócios e técnicas, promovendo a colaboração em projetos de IA.
- A Synthetic Data Studio gera conjuntos de dados sintéticos para testes e treinamento de modelos quando os dados reais são limitados ou restritos.
- O Fine-Tuning Studio adapta modelos de código aberto com conjuntos de dados específicos da empresa para maior relevância e precisão.
- RAG Studio cria pipelines RAG que conectam LLMs (como OpenAI, Anthropic, Amazon Bedrock) a dados privados relevantes para gerar resultados contextuais e fundamentados.
- O Agent Studio possibilita a criação de fluxos de trabalho agentivos em múltiplas etapas que utilizam modelos, MCPs, APIs e fontes de dados internas para automatizar tarefas específicas de cada domínio.
Todas essas capacidades operam no open lakehouse (nas fundações do Iceberg), proporcionando às equipes o acesso governado e sem cópia aos dados necessários para tarefas específicas.
Cloudera MCP Server
A Cloudera também está ampliando a abertura de sua plataforma de IA por meio de uma série de serviços MCP emergentes, começando pelo servidor MCP de código aberto Cloudera AI Workbench. Este serviço foi projetado para integração de sistemas de IA, possibilitando recursos de agentes e de chamada de ferramentas dentro do AI Workbench. Ele disponibiliza a estrutura para que os LLMs interajam com segurança com recursos e componentes do Cloudera AI Workbench, trazendo modelos, dados e aplicações para fluxos de trabalho corporativos automáticos. Nessa arquitetura, agentes inteligentes podem raciocinar, agir e automatizar tarefas em todo o ambiente confiável e governado da Cloudera, mantendo a segurança, o controle e a auditabilidade exigidos em setores regulados.
Serviço de Inferência de IA Cloudera
O Cloudera AI Inference Service leva modelos para produção com escalonamento automático, alta disponibilidade e observabilidade de fim-a-fim. Oferece suporte tanto a modelos de aprendizado de máquina tradicionais quanto a grandes modelos de linguagem (LLMs), apresentando previsões e respostas com baixa latência. Os modelos podem ser implementados como endpoints REST ou gRPC com segurança de nível empresarial, garantindo acesso confiável e consistente por parte de aplicativos e agentes.
O Cloudera AI Registry, integrado à camada de inferência, oferece um gerenciamento centralizado do ciclo de vida do modelo com APIs compatíveis com MLflow para rastreamento, versionamento, armazenamento de artefatos e linhagem. Você pode escolher entre várias opções de modelos de linguagem abertos e corporativos, como LlaMa, Cohere, Gemma e Mistral.
A camada de inferência também inclui monitoramento e observabilidade embutidos, possibilitando que equipes acompanhem latência, taxa de processamento e deriva do modelo, mantendo total linhagem e conformidade por meio da governança SDX. Isso garante que as previsões do modelo sejam explicáveis e rastreáveis, o que é um requisito fundamental para IA de nível empresarial.
O futuro é impulsionado pela IA e a IA é alimentada por todos os dados.
O sucesso da IA depende tanto da arquitetura de dados quanto da capacidade do modelo/agente. O lakehouse oferece essa base, unificando cargas de trabalho analíticas, operacionais e de IA em um único plano de dados governado. Quando construído com base em padrões abertos, garante que dados, metadados e modelos possam interoperar entre ferramentas, nuvens e equipes sem atritos.
Em conjunto, o Cloudera AI Workbench, o AI Inference Service e o AI Registry integrado completam o ciclo de vida de dados para IA em uma base de arquitetura aberta e integrada. Construída diretamente sobre tabelas Iceberg governadas e acesso aberto a metadados, essa estrutura garante que cada modelo, prompt e agente opere com dados confiáveis e versionados.
O futuro da IA corporativa não será definido por pilhas proprietárias, mas por fundações abertas que unificam dados, governança e inteligência por meio de padrões compartilhados e interoperabilidade transparente.
Para saber mais sobre como preparar, integrar e analisar dados em escala com segurança com o Cloudera, confira nossas demonstrações de produtos ou inscreva-se para um teste gratuito de 5 dias.
